All Articles
Cross-Industry Standard Process for Data Mining (CRISP-DM)

Structured data mining has Knowledge Discovery in Databases (KDD) methodology, which has been in existence since the 1990s. KDD offers a process framework that includes a set of computational tools and theories aimed at extracting insights from data. Based on this, KDD has several distinctive features, varying from data access and storage to human-computer interaction, visualization and interpretation of results.
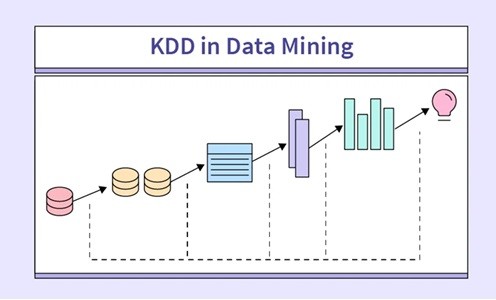
Figure 1: Illustration for the KDD Process
[Image Source: https://www.scaler.com/topics/data-mining-tutorial/kdd-in-data-mining/]
In the year 2000, as a direct response to some of the data mining challenges, a new methodology which hinged on the evolving industry needs was developed and named the Cross-Industry Standard Process for Data Mining (CRISP-DM). It leveraged the original KDD model and its diverse versions. As widely accepted, CRISP-DM is an offshoot from KDD and includes six phases. These executions are implemented iteratively which makes it stand out when compared with the initial KDD that adopts a step-by-step execution process executed serially. The main target of CRISP-DM, which is also similar to that of KDD, is to provide practitioners with a framework by which they can implement data mining on large data sets. However, due to the six main steps and 24 tasks and outputs of the CRISP-DM, it is considered a more refined version than the KDD model.
The main target of CRISP-DM, which is also similar to that of KDD, is to provide practitioners with a framework by which they can implement data mining on large data sets. However, due to the six main steps and 24 tasks and outputs of the CRISP-DM, it is considered a more refined version than the KDD model. Ultimately, SEMMA (Sample, Explore, Modify, Model and Assess) also emerged from the KDD model in 2005 by the SAS Institute, an organization behind Enterprise Miner, designed with the aim of streamlining fundamental tasks of data mining.
The KDD model includes the following important steps:
STEP 01: Learning application domain: understanding the application domain and relevant information is needed in the first step. This should be followed by pinpointing the exact objective of the KDD process from the standpoint of the customer.
STEP 02: Dataset creation: the second stage focuses on choosing a particular data set while concentrating on the data samples or variable subset which needs to be discovered.
STEP 03: Data cleaning and processing: the removal of outliers and noise from the selected data set with basic operation techniques is the focus of the third step. Sourcing and collating the needed information, accounting for noise, analyzing the techniques required to manage the missing data fields, and reporting on schema, data types and mapping of omitted values are also focused on in this step.
STEP 04: Data reduction and projection: strategies for proper data representation are considered based on the task to be achieved, whilst also executing transformation techniques to reveal optimal features set for the data.
STEP 05: Choosing the function of data mining: the fifth step is more concerned with defining the target outcome (e.g. classification, clustering, summarization, and regression).
STEP 06: Choosing the data mining algorithm: this involves identifying a tool(s) for finding patterns in the data set, determining which parameters and models are suited, and pairing a specific method of data mining with the general aims of the KDD process.
STEP 07: Data mining: the work of mining the data is conducted in the seventh step which includes identifying patterns of interest in a data set.
STEP 08: Interpretation: this involves sorting and removing all unwanted and redundant patterns, with the relevant patterns being represented in an easily understandable way to decision-makers.
STEP 09: Using discovered knowledge: this final step involves incorporating the results with the performance system, which is then reported and documented to wider stakeholders.
The KDD process has gained significant traction in academic and industrial spheres. A review of the timeline-based evolution of data mining methodologies indicates that the original KDD data mining model acted as a benchmark for other models and processes, thereby helping to address its deficiencies and weaknesses. As such, the initial KDD framework has been substantially extended.
Although CRISP-DM builds upon KDD, it involves six stages that are iteratively implemented. The iteration feature of the CRISP-DM model is the standout feature when compared to the original KDD that implements its steps sequentially.
CRISP-DM, similar to KDD, is focused on empowering decision-makers with a framework by which they can apply data mining to various sources of Big Data. The key idea behind such a framework is to ensure a well-structured and systematic process of Big Data management that can be implemented and followed by the analysts and managers in any organization. The process covers steps related to understanding a specific business issue, data preparation, modelling, and deployment, amongst other activities related to data analytics, as discussed in detail below.
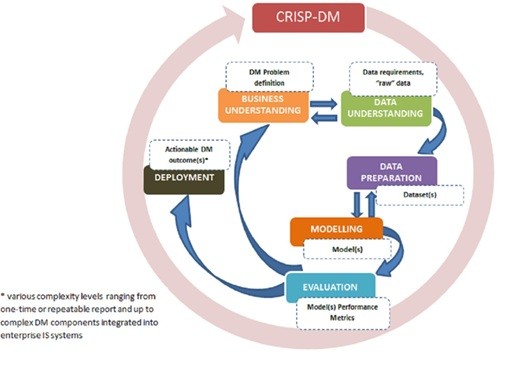
Figure 2: CRISP-DM phases and key outputs
[Image Reference: Plotnikova, V., Dumas, M., & Milani, F. P. (2022). Applying the CRISP-DM data mining process in the financial services industry: Elicitation of adaptation requirements. Data & Knowledge Engineering, 139, 102013. https://doi.org/10.1016/j.datak.2022.102013]
With its six steps and 24 tasks/outputs CRISP-DM, is considered more sophisticated than KDD. The steps of CRISP-DM are as follows:
Phase 1:
Business understanding: gaining an in-depth understanding of the requirements and objectives of the project from a business perspective is crucial. This is then followed by the conversion of these perspectives into a data mining problem. This first step also includes a presentation of the basic plan needed to achieve its goal.
Phase 2:
Data understanding: this stage involves data collection, which is followed by several activities aimed at providing greater insights into the data, including discovering data quality issues, detecting and developing hypotheses and identifying immediate insights into data.
Phase 3:
Data preparation: the third stage focuses on the processes needed to transform the initial raw data into the final data set. Data preparation tasks are iterated through a number of times.
Phase 4:
Modelling phase: this stage involves selecting and engaging various modelling techniques followed by calibrating their parameters. In most cases, different techniques can be used to solve the same data mining challenge.
Phase 5:
Evaluation of the model(s): in this step, the quality perspective is first considered before moving to the final model deployment which examines the model(s) and chooses the best one to achieve the business objectives. The ways to utilise the data mining outcomes must have been agreed upon by the end of this stage.
Phase 6:
Deployment phase: this final stage involves the deployment of the models to enable end-users to utilize the data as a tool for decision-making. Even in situations where the purpose of the model is to provide more information about the data, the insights extracted still need to be organized and presented for use by the users of this process. Based upon the requirements, the deployment phase could involve a simple step, such as producing reports, or a more complex, iterative data mining process.
Reference:
Plotnikova, V., Dumas, M., & Milani, F. P. (2022). Applying the CRISP-DM data mining process in the financial services industry: Elicitation of adaptation requirements. Data & Knowledge Engineering, 139, 102013. https://doi.org/10.1016/j.datak.2022.102013

Mr. W.M.C.J.T. Kithulwatta
Lecturer at the Department of Information and Communication Technology
Faculty of Technological Studies
Uva Wellassa University of Sri Lanka